
- 1. Seq2Seq Model
- 2. 机器翻译中的 Attention model
- 3. 视觉应用中的 Attention Model
- 4. 机器翻译中的 Self-Attention
- 5. 视觉中的 Self-Attention
- 6. GAN的 Self-Attention
- 7. 基于 Attention 的字符识别
- 8. 基于 Attention 的图片生成
- 9. 强化学习中结合 Attention
- 9.1. Deep Attention Recurrent Q-Networ
- 9.2. Control of Memory, Active Perception, and Action in Minecraft
- 9.3. Multi-focus Attention Network for Efficient Deep Reinforcement Learning
- 9.4. Relational Deep Reinforcement Learning
- 9.5. Relational recurrent neural networks
- 10. Multi-Agent 中结合 Attention
Attention Mechanism 非常流行,广泛用于机器翻译、语音识别、计算机视觉等很多领域。它之所以这么受欢迎,是因为 Attention 赋予了模型区分辨别的能力。深度学习中的注意力机制从本质上和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。

人类的注意力机制可以使我们专注于某个具有“高分辨率”的区域(即查看黄色方框中的尖耳),同时以“低分辨率”感知周围的图像(观察背后的雪景和服装),最后调整聚焦点然后做出推断,这是一只狗。
给定图像的一小块,图像的其他区域包含了这一小块区域应该显示什么的线索。我们希望在黄色的方框中看到尖尖的耳朵,是因为我们看到了狗的鼻子,右边的尖耳朵以及柴犬的眼睛。然而,底部的毛衣和毯子不如那些狗的特征有用。
同样地,我们可以用一句话或近距离的上下文来解释单词之间的关系,当我们看到吃的时候,我们期待着很快会遇到一个食物的单词。
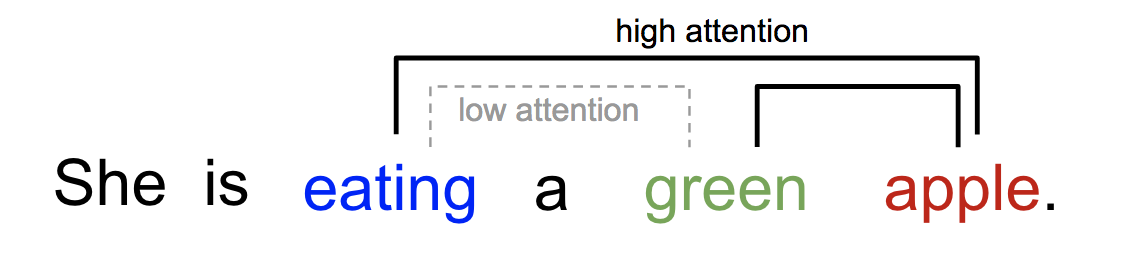
对于上图来说,eating 和 apple 有着更高的 attention,与它更近的 green 反而 attention 低。
Seq2Seq Model
Seq2Seq 全名是Sequence to Sequence,也就是从序列到序列的过程。Seq2Seq常见情形为机器翻译,Seq2Seq 包含两部分 Encoder 和 Decoder。一旦将句子输入 Encoder ,即可从 Decoder 获得目标句。
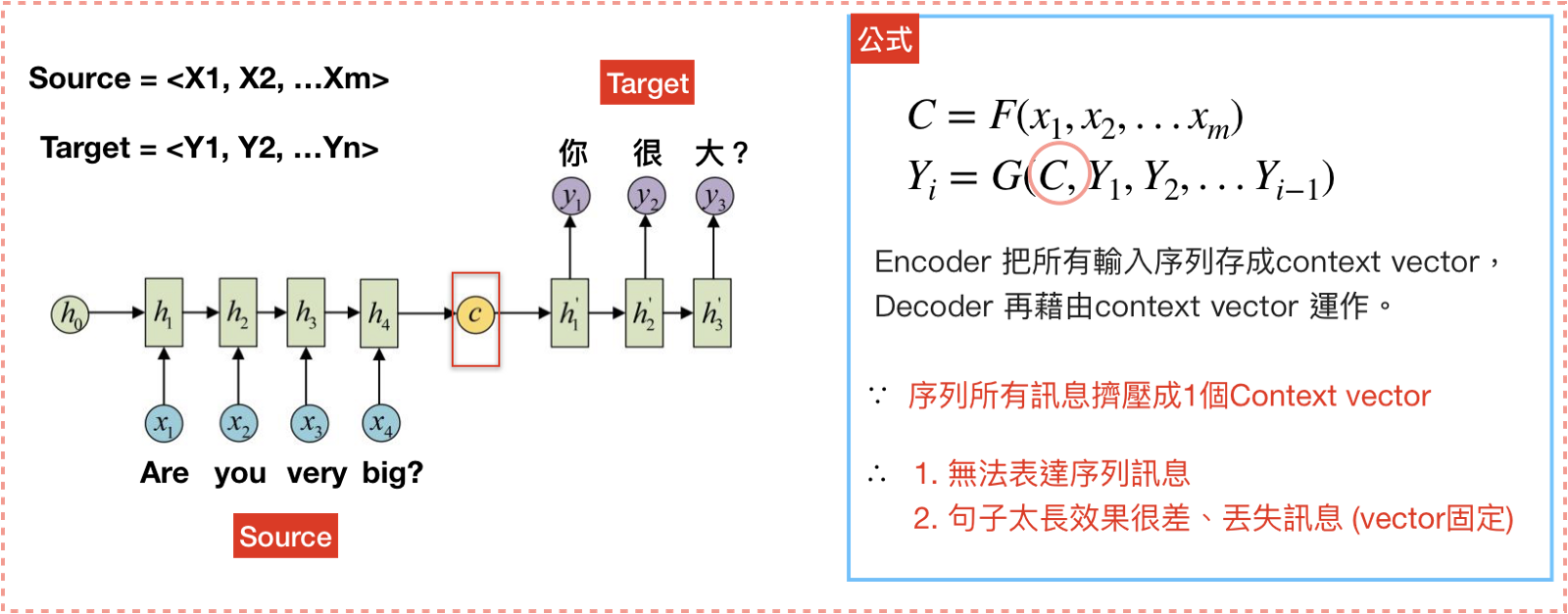
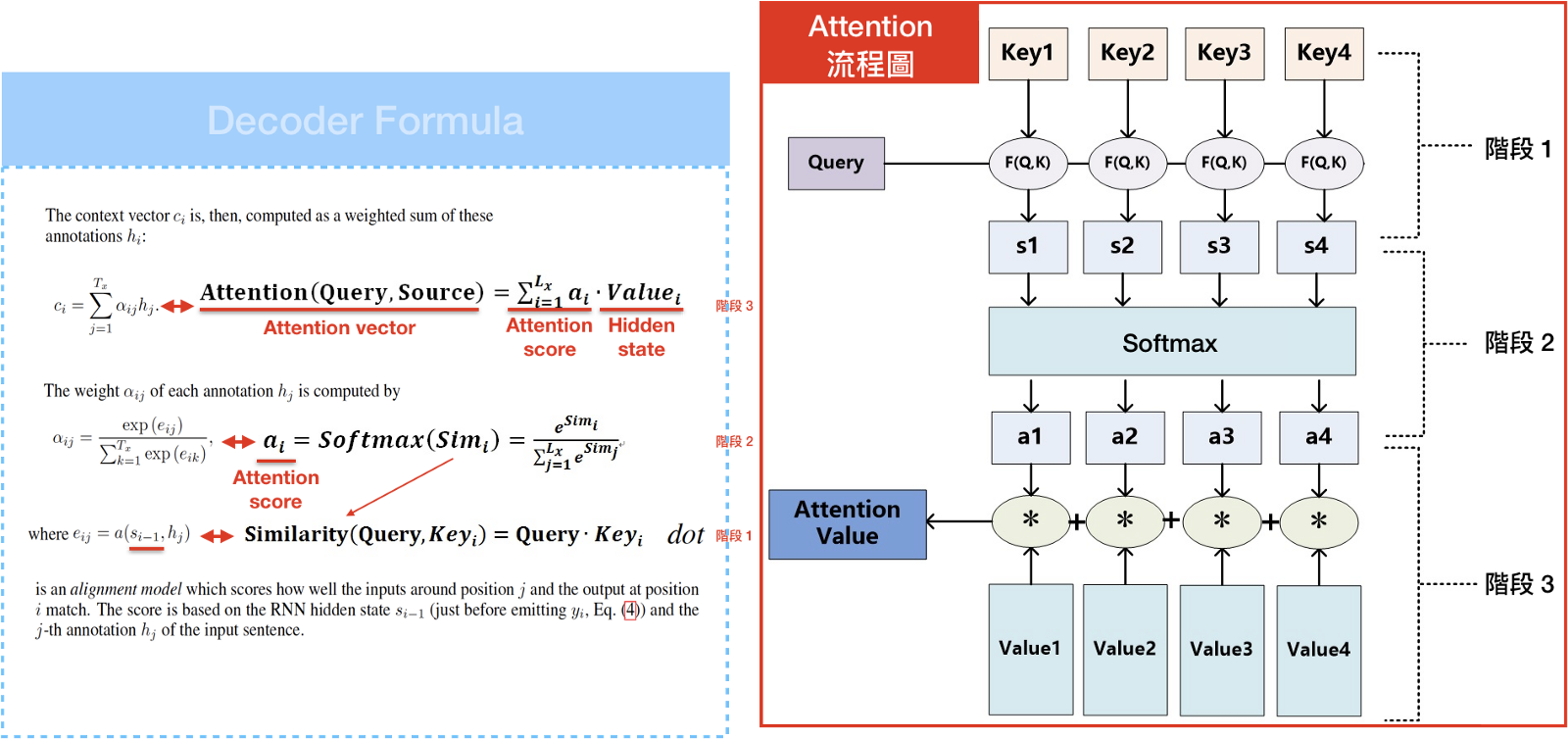
图中的 C 指的是 context vector ,context vector 可以想象成一个含有所有输入信息的向量,也就是 Encoder 当中最后一个 hidden state。Encoder 将输入句压缩成固定长度的 context vector ,context vector 即可完整表达输入句,再透过 Decoder 将 context vector 内的信息产生输出。
这样做存在两个问题:
- 把输入 x 的所有信息压缩到一个固定长度的隐向量 C 。当输入句子长度很长时,特别是比训练集中最初的句子还长时,模型的性能急剧下降。
- 把输入 x 编码成一个固定长度的 C ,对于句子中每个词都赋予相同的权重。但是词与词之间的翻译一般有对应关系,如果对输入的每个词赋予相同的权重,没有表现出翻译的区分度。
机器翻译中的 Attention model
前面展示的 Encoder-Decoder 模型是没有体现出 注意力 的。观察下目标句子中每个单词的生成过程:
$$y_1 = G(C)$$
$$y_2 = G(C,y_1)$$
$$y_3 = G(C,y_1,y_2)$$
其中 G 是非线性的变换函数。可以发现,在生成目标句子的单词时,无论生成哪个单词,它们使用的输入句子 Source 的语义编码 C 都是一样的,没有任何区别。这意味着 Source 中每个单词对生成某个目标单词 $y_i$ 来说影响力都是相同的,没有体现出注意力。
在 Attention model 中,Encoder 和 Seq2Seq 一样是从输入句 $ x_1,x_2,x_3…x_m$ 产生 $ h_1,h_2,h_3…h_m $的 hidden state, 再计算目标句 $ y_1,y_2,y_3..y_m $。差别就在于 context vector 怎么计算。
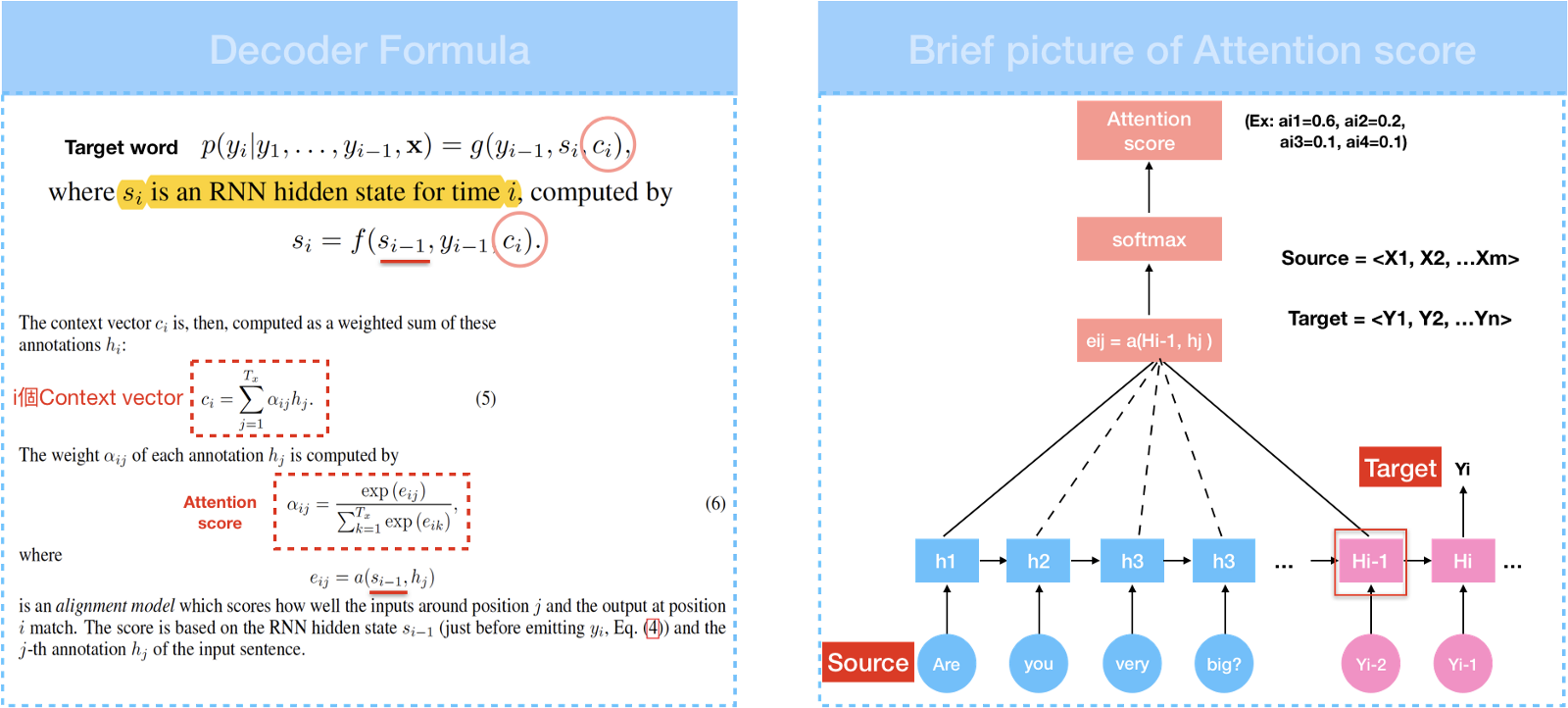
$$C_i = \sum_{j=1}^{T_x} \alpha_{ij}h_j$$
Context vector 是通过 attention score $\alpha$ 乘上输入句的 hidden state 加权求和。Attention score 用来衡量输入句中每个文字对目标句中的每个文字所带来的重要性的程度。
$$ Attention \; score \; \alpha_{ij} = \frac{exp(e_{ij})}{\sum_{k=1}^{T_x}exp(e_{ik})} $$
其中$$Socre \; e_{ij}=a(s_{s_{i-1}},h_j)$$
在计算 Score 中,a 代表Alignment model,它根据输入字位置 j 和输出字位置 i 计算这两者的关联程度计算出 $score \; e_{ij}$。
下表是几种常见的 attention mechanisms 和对应的 alignment score functions:

有了 $Score \; e_{ij}$之后,即可通过 softmax 计算出 Attention score ,Context vector 也可以得到。我们可以将 Context vector 列为矩阵,通过此矩阵看到输入端文字和输出端文字间的对应关系。
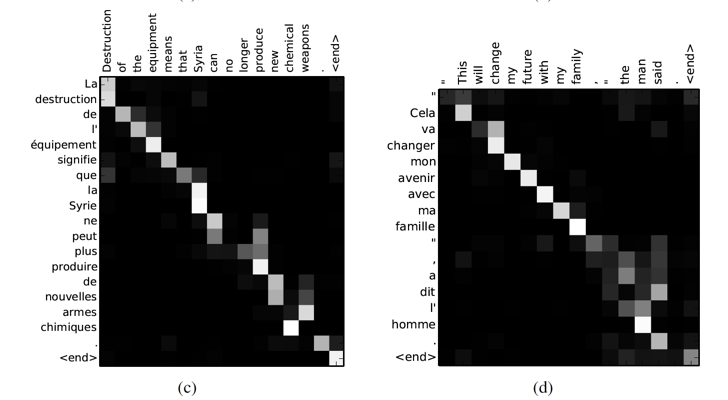
x 轴和 y 轴分别对应输入轴和输出轴,每个像素表示输入句中的第 j 个文字对应目标句中的第 i 个文字的权重大小,即 Attention score (0:黑,1:白)。
可以把 Attention 理解为从大量信息中有选择地筛选出少量最重要的信息并聚焦到这些重要信息上,忽略大多不重要的信息。其中聚焦的过程体现再权重系数的计算上,权重越大越聚焦于对应的特征值上,即权重代表了信息的重要性,而对应特征是其需要重点学习的知识。
Attention 机制应用分为三步:
- 根据已有的结果与隐变量 h 建立相关性,即 $Socre \; e_{ij}=a(s_{s_{i-1}},h_j)$
- 对步骤一中的关系原始分进行归一化处理,即 $ Attention \; score \; \alpha_{ij} = \frac{exp(e_{ij})}{\sum_{k=1}^{T_x}exp(e_{ik})} $
- 根据归一化的权重系数对隐变量 h 中的数值进行加权求和,即 $C_i = \sum_{j=1}^{T_x} \alpha_{ij}h_j$
视觉应用中的 Attention Model
与机器翻译中的 Attention 应用思想类似,视觉中的 Attention 其实也是学出一个权重分布,再拿这个权重分布施加在原来特征之上。不过施加权重的方式略有差别,视觉应用一般有以下几种施加方式:
1. 加权可以保留所有的分量做加权(soft attention)
2. 可以在分布中以某种采样策略选取部分分量做加权(hard attention)
3. 加权可以作用在原图上
4. 加权可以作用在空间尺度上,给不同空间区域加权
5. 加权可以作用在 Channel 尺度上,给不同通道特征加权
6. 加权可以作用在不同时刻的历史特征上 等
soft 和 hard attention 的定义起源于 Show, Attend and Tell: Neural Image Caption Generation with Visual Attention 文章。图像标注(Image caption),就是从图片中自动生成一段描述性文字,类似于“看图说话”。机器不仅要检测出图像中的物体,而且要理解物体之间的相互关系,最后还要用合理的语言表达出来。

Image caption model with LSTM
在讨论 attention 之前,我们快速回顾以下如何使用 LSTM 进行图像标注,图像标注同样离不开 Encoder-Decoder 结构。
Encoder使用 CNN 从图片提取特征 X ,作为 LSTM cells(Decoder) 的输入。每个 LSTM cell 接受上一个隐状态 $h_{t-1}$ 和 图像特征 X ,输出新的隐状态 $h_{t}$。最后我们使用 $h_{t}$ 对下一个单词进行预测。
$$h_t = f(x,h_{t-1})$$
$$next word = g(h_t)$$
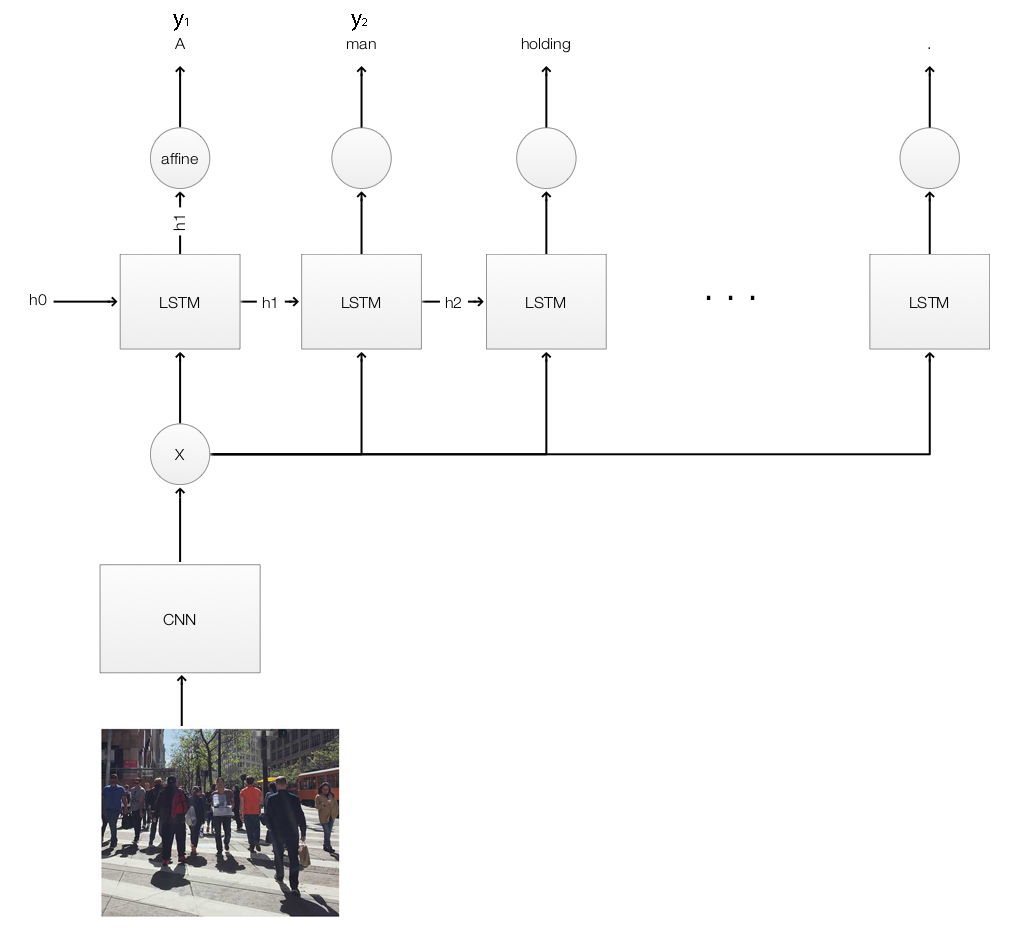
Attention
LSTM 与 Attention 模型之间的关键区别在于 Attention 会关注特定区域和对象,而不是平等地处理整个图像。例如,标注的一开始,我们首先 Attention 走向我们的这个人。我们预测的第一个单词为 “A”,并将上下文更新为 “A”。我们保持 Attention 的区域不变,预测下一个单词为 “man”。对于接下来的预测,我们的 Attention 转移到他手里拿了什么。通过不停的探索和转移 Attention 区域,我们生成了这张图片的标注 “ A man holding a couple plastic containers is walking down an intersection towards me.”

从数学来看,我们替换 LSTM 模型中的 X:
$$h_t = f(x,h_{t-1})$$
使用 Attention module:
$$h_t = f(attention(x,h_{t-1}),h_{t-1})$$
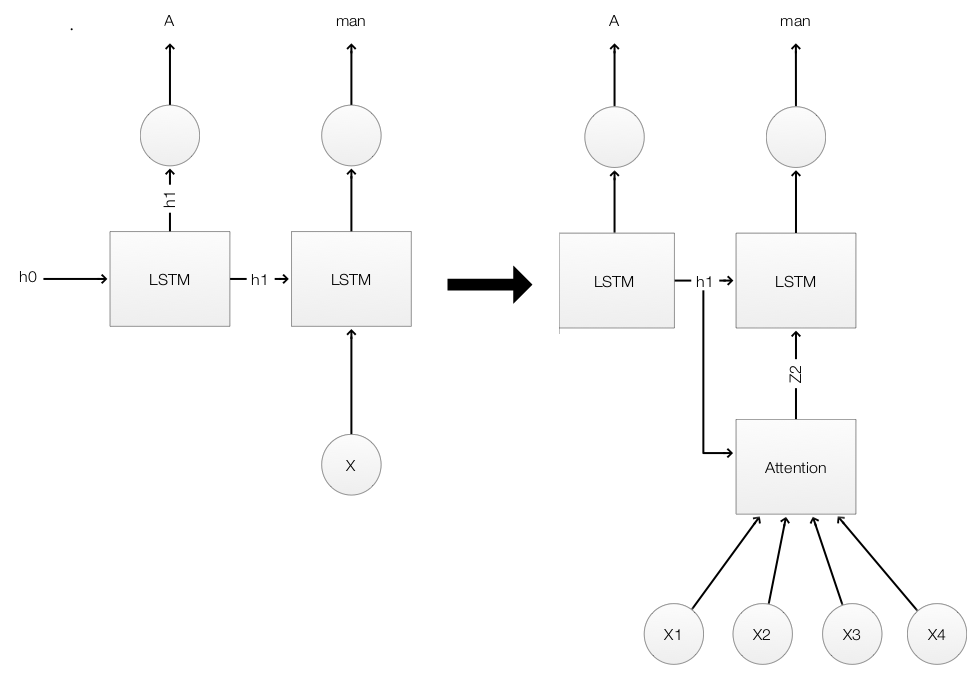
Attention module 的输入为 $h_{t-1}$ 和 四个 CNN 提取的高维空间区域($x_1,x_2,x_3,x_4$)。为了更好的理解,下图将 features map 可视化为它可能表示的原图。

Soft attention
Soft attention 的计算和前文介绍的机器翻译Attention model 方法一致。
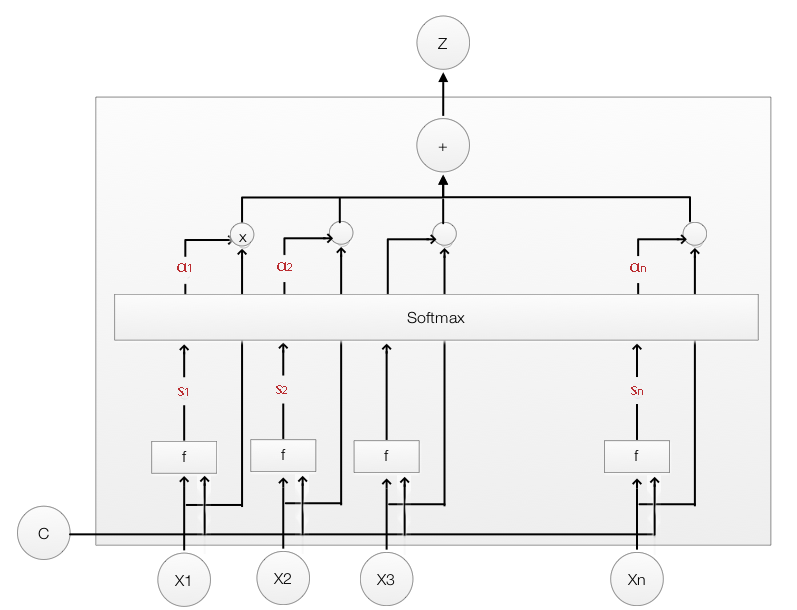
由于使用了Attention机制,我们可以根据权重系数 $\alpha$ 的大小,得知在生成每个词时模型关注到了图片的哪个区域。下图展示了一些例子,每个句子都是模型自动生成的,在图片中用白色高亮标注了生成下划线单词时模型关注的区域:

使用 Soft attention 的整个模型光滑、可微,利用反向传播来进行 end-to-end 训练。
Hard attention
在 Soft attention 中,我们为每个 $x_i$ 都计算了一个权重 $ Attention score \alpha$,并使用它作为计算 LSTM 输入的加权平均。而 Hard attention 使用 $\alpha$ 表示是否选择 $x_i$ 作为 LSTM 的输入。
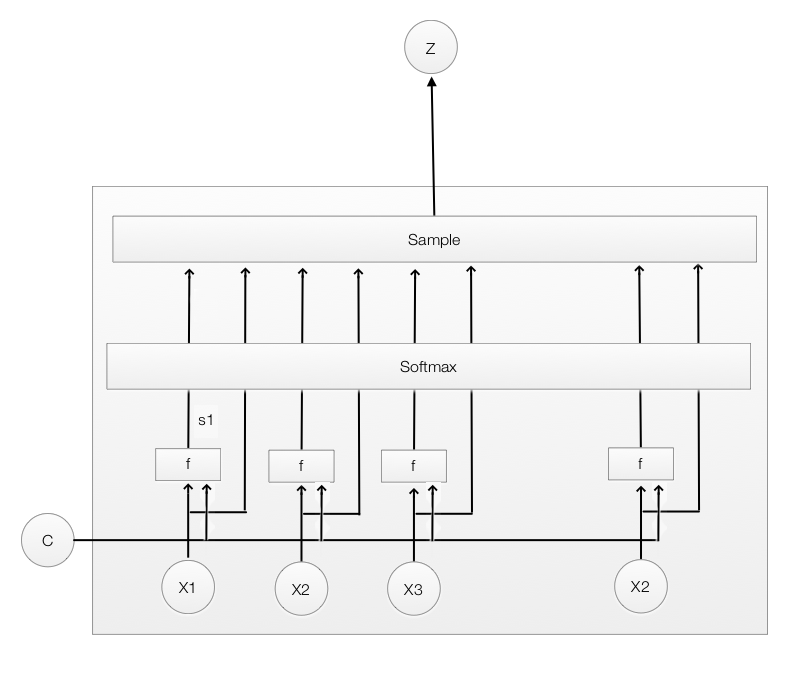
Hard Attention是一个随机的过程。Hard Attention不会选择整个encoder的输出做为其输入,Hard Attention 会依概率 Si 来采样 encoder 输出的一部分来进行计算,而不是整个encoder的输出。为了实现梯度的反向传播,需要采用蒙特卡洛采样的方法来估计模块的梯度。
Hard Attention 无法嵌入到网络中进行学习,这也导致 Soft Attention 更受欢迎。
相关论文:
soft attention:
esidual Attention Network for Image Classification
Squeeze-and-Excitation Networks
CBAM: Convolutional Block Attention Module
hard attention:
Recurrent Models of Visual Attention
- RAM 应用强化学习机制,在每一个时间点,agent 只能在一个局部的区域获取图像部分信息;
- 根据后的部分信息提取网络特征,对局部图像进行分类,弱分类正确 奖励 +1,否则 +0;
- 根据奖励信息引导 agent 寻找下一个局部区域,从而获得图像中有效的局部位置。
这个寻找图像局部区域的过程,可以理解为 RAM 算法学习Hard Attention 的过程。
Multiple Object Recognition with Visual Attention
作用在原图:
Recurrent Models of Visual Attention
Multiple Object Recognition with Visual Attention
Hierarchical Attentive Recurrent Tracking (使用了分层 待补坑)
作用在空间区域:
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Residual Attention Network for Image Classification
Squeeze-and-Excitation Networks
BAM: Convolutional Block Attention Module
作用在时间序列:
Action recognition using visual attention
Attending to Distinctive Moments: Weakly-Supervised Attention Models for Action Localization in Video
Attention-aware deep reinforcement learning for video face recognition
3D Attention-Based Deep Ranking Model for Video Highlight Detection
机器翻译中的 Self-Attention
之前的 Attention 存在以下几个方面的问题
- Attention 机制过度依赖在 Encoder-Decoder 架构上
- Attention 机制依赖于 Decoder 的循环解码器,所以依赖于 RNN、LSTM 等循环结构
- Attention 依赖循环结构,无法做到并行训练,训练速度受到影响
- Attention 本质是通过对比输入空间和输出空间的特征,学习 Attention 权重因子
- Attention 忽略了输入句中文字间的关系,同时也忽略了输出句中文字间的关系
Self-Attention 脱离了 Encoder-Decoder 架构和循环结构,并且针对输入空间特征或者输出空间特征单独学习权重因子,它不需要同时依赖两个空间的联系。
Self-Attention 是 Google 在 “Attention is all you need” 论文中提出的 The Transformer 模型中主要的概念之一。
在 Attention model 是从输入句 $ x_1,x_2,x_3…x_m $ 产生 $ h_1,h_2,h_3…h_m $的 hidden state,通过 $Attention \; socre \; \alpha $ 乘上 input 的加权求和得到 Content vector C。有了 Content vector C 和 hidden state vector 即可计算目标句 $ y_1,y_2,y_3..y_m $。
我们从另外一个角度来看 Attention model :
输入句的每个文字是由一些列成对的
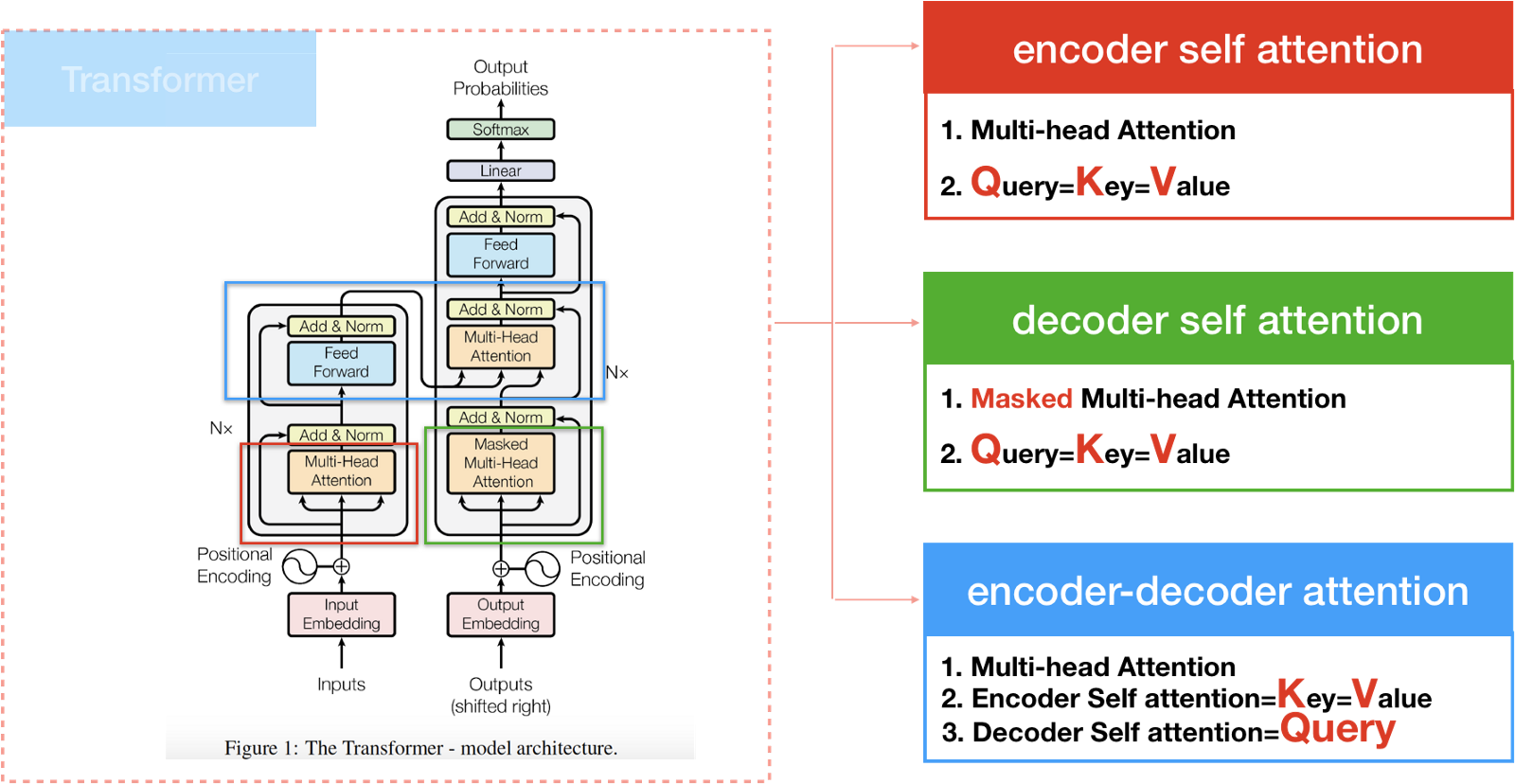
The Transformer 计算 Attention 的方式有三种,如下图
- Encoder self attention 存在于 Encoder 中
- Decoder self attention 存在于 Decoder 中
- Encoder-Decoder attention 这种 Attention 和之前的 Attention 相似
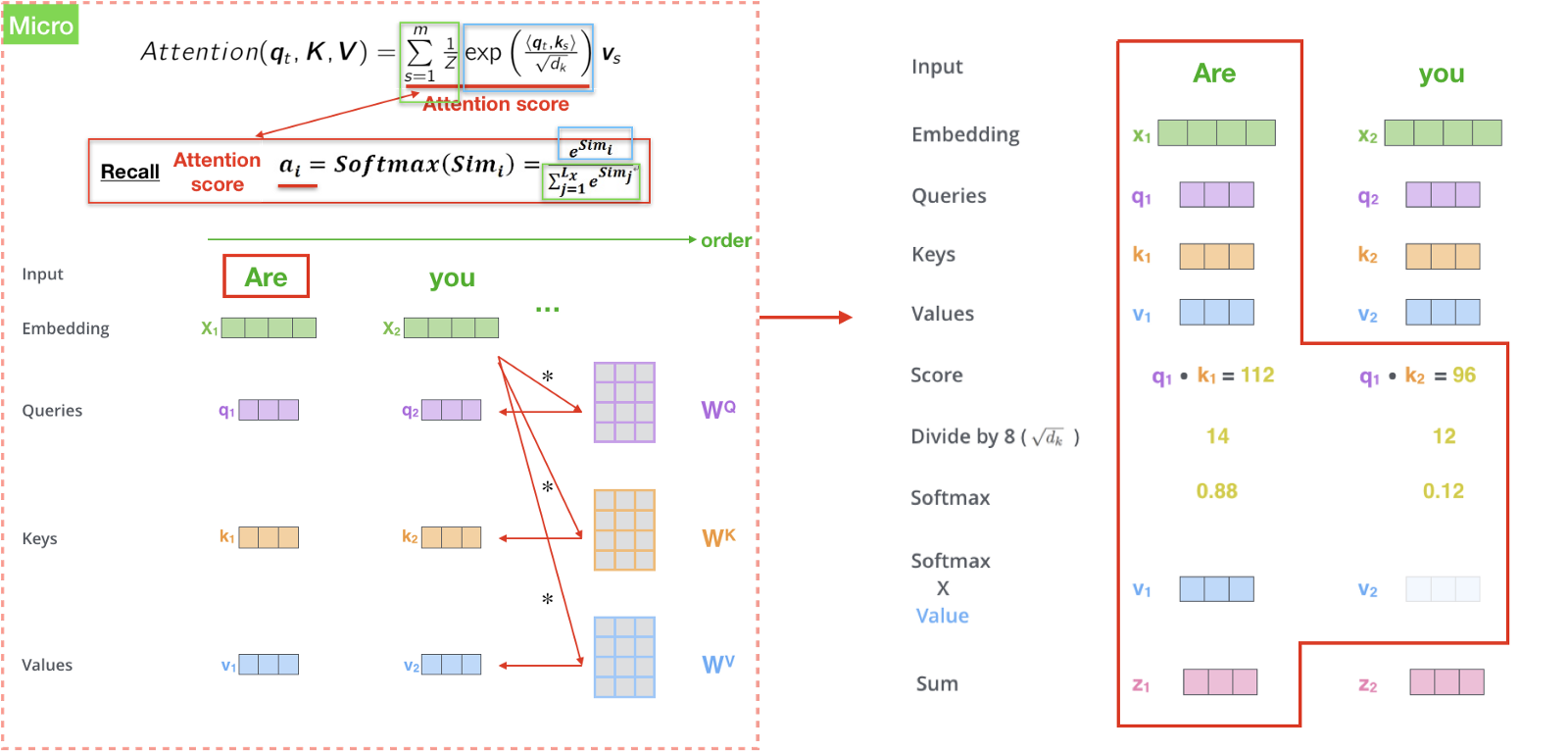
计算 Encoder self attention
首先,创建 Encoder 的输入向量 Q 、 K 、 V,举个例子,“Are you very big?”中的每个单词的隐向量都有自己的 Q 、 K 、 V。
接着计算 $score (q_t,k_s)$ ,和 Attention model 中的 $score e_{ij}$ 类似。假设我们计算第一个单词 “Are” 的 self-attention ,我们将输入句中的每个单词 “Are” “you” “very” “big” 分别和 “Are” 去做比较,这个分数决定了我们在 encode 某个特定位置的单词时,应该给予多少 Attention 。所以,我们计算位置 1 的 Self-attention, 第一个分数是 $Similarity(Are,Are)$,第二个分数是$Similarity(Are,you)$,以此类推。
然后将得到的分数做一层 softmax 得到 Attention Score。代表我们应该放多少 Attention 在这个位置。
最后一步就是把 Attention Score 乘上 Value,然后加总得到 Context vector Z。
整个计算过程如下图所示:
计算 Decoder self attention
Decoder 的运作模式和 Encoder 类似,不同的地方在于,为了避免解码时,还在翻译前半段,就突然得到了后半段的句子,所以会在计算 self-attention 时的 softmax 前 mask 掉未来的位置。
Encoder-Decoder attention
Encoder-Decoder attention 和 Encoder/Decoder attention 不一样,它的Query 来自于 Decoder attention,而 Key 和 Value 则是来自于 Encoder 的 output。
Multi-head attention
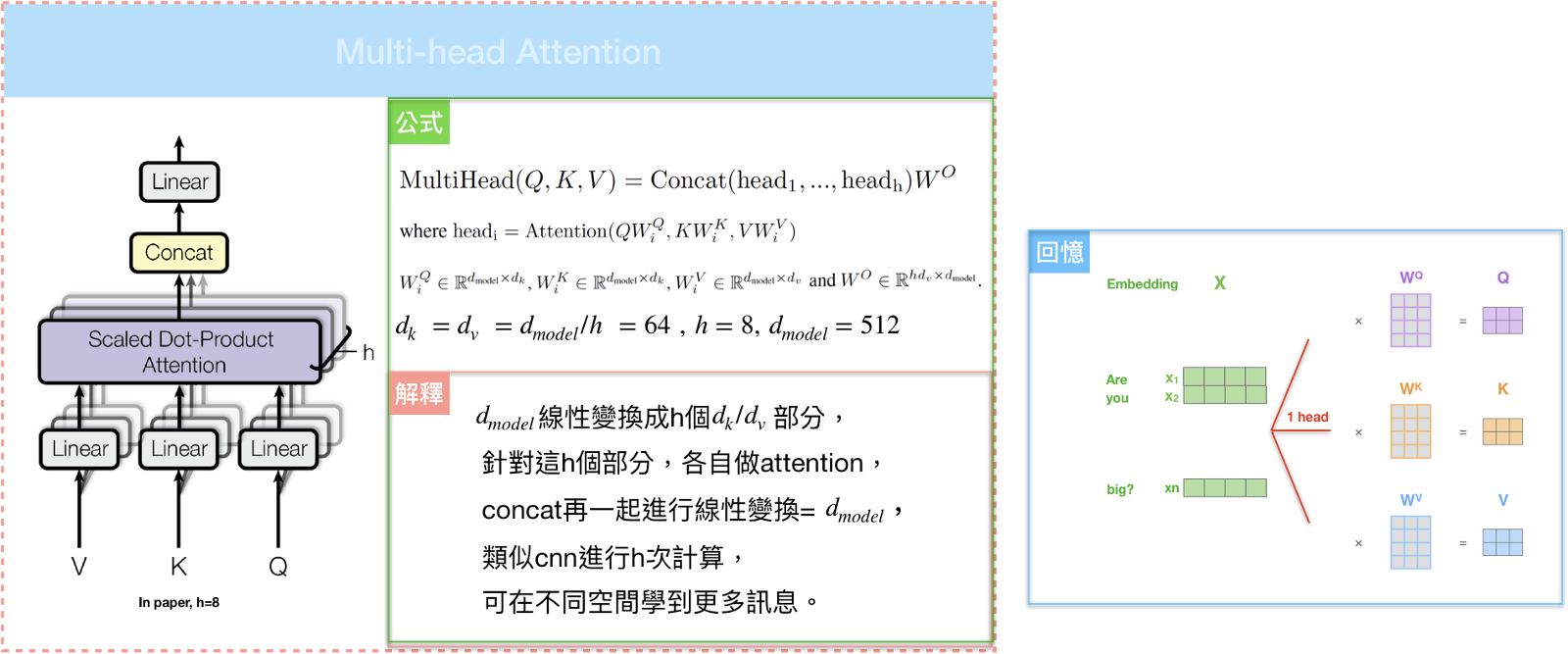
如果我们只计算一个 attention ,很难捕捉到句子中所有空间信息,为了优化模型,论文提出了一个新的做法:Multi-head attention。不仅仅对 Key 、 Value 、Query 做单一的 attention ,而是把 Key 、 Value 、Query 线性映射到不同的空间 h 次,再各自做 attention。这样就可以从不同的维度和表示的子空间里学习到相关的信息。
通过 The Transformer ,我们可以使用 Multi-head attention 来解决并行化和计算复杂度过高的问题,依赖关系也可以通过 Self-attention 中单词与单词之间的比较方式来克服。
SNAIL
Transformer 模型没有 RNN 或者 CNN 结构,即使引入位置相关的编码,也是一种序列顺序的弱整合,对于位置敏感的任务,比如强化学习,这是一个问题。
待补坑
视觉中的 Self-Attention
Non-local Neural Networks 在捕捉长距离特征之间依赖关系的基础上提出了一种非局部信息统计的注意力机制。
不管是 CV 任务还是 NLP 任务,都需要捕捉长范围依赖。在时序任务中,RNN 是一种主要的捕获长范围依赖手段,而在 CNN 中是通过堆叠多个卷积块来形成的大感受野。目前的卷积和循环结构都是在空间或者时间上的局部操作,长范围的依赖捕获是通过重复堆叠,并且反向传播得到,会有一些问题:
- 捕获长范围特征依赖需要累计很多层的网络,导致学习效率太低
- 当需要在比较远的位置之间来回传递消息时,卷积或时序局部操作很困难
- 由于网络需要累计很深,需要小心的设计模块和梯度
Local & Non-local
Local 这个词说的是感受野。以卷积操作为例,它的感受野大小就是卷积核大小,只考虑了局部区域, 因此都是 Local 运算。相反,Non-Local 就是值感受野很大,而不仅仅是一个局部区域。
作者提出了一个泛化、简单、可直接嵌入到当前网络的非局部算子,可以捕获时间、空间和时空的长范围依赖。这样设计的好处:
- 相比较于不断堆叠卷积和 RNN 算子,Non-local 直接计算两个位置(可以是时间位置、空间位置和时空位置)之间的关系即可快速捕捉长范围依赖
- Non-local 的计算效率高
- Non-local 可以保证输入尺度和输出尺度不变,这种设计使得 Non-local block 可以很容易嵌入到网络架构中去
Non-local Block
为了能够当作一个组件接入到以前的神经网络中去, Non-local 操作的输入和输出大小一致,具体来说,公式如下:
$$y_i = \frac{1}{C(x)} \sum_{\forall j} f(x_i,x_j)g(x_j)$$
公式中,输入是 x ,可以使图像、序列、视频等,输出是 y。 i 是输出特征图的一个位置,j 是输入所有可能位置索引, f 是相似性计算函数,计算输出中第 i 个位置和其他所有位置的相似性。 g 是一个简单的映射函数,可以看成计算一个点的特征,也就是说,为了计算输出层的一个点,需要将输入的每个点都考虑一遍,而且考虑的方式很像 attention :输出的某个点在原图上的 attention ,而 mask 则是相似性给出。参看下图。

为了能让 Non-local操作作为一个组件,可以直接插入任意的神经网络中,作者把 Non-local 设计成 residual block 的形式,让 Non-local操作去学 x 的 residual:
$$z_i = W_z \cdot y_i + x_i$$
$W_i$ 实际上是一个卷积操作,它的输出 channel 数跟 x 一致。这样以来,Non-local 操作就可以作为一个组件,组装到任意卷积神经网络中。
嵌入在 action recognition 框架中的attention map 可视化效果:

图中的箭头表示,之前若干帧中的某些像素对最后图(当前帧)的脚关节像素的贡献关系。由于是 soft-attention,其实每帧每个像素对其有贡献关系,图中黄色箭头是把贡献最大的关系描述出来。
跟全连接层的联系
我们知道,Non-local block 利用两个点的相似性对每个位置的特征做加权,而全连接层则是利用 position-related 的 weight 对每个位置做加权。于是,全连接层可以看成 Non-local block 的一个特例:
- 任意两点的相似性仅跟两点的位置有关,而与两点的具体坐标无关,即 $f(x_i, x_j)=w_{ij}$
- g 是identity函数, $g(x_i)=x_i$
- 归一化系数为1。归一化系数跟输入无关,全连接层不能处理任意尺寸的输入。
跟 Self-attention 的联系
Embedding的1*1卷积操作可以看成矩阵乘法:
$\theta(\mathbb{x}_i)= W_{\theta} \cdot \mathbb{x}_i; \quad \phi(\mathbb{x}_j)=W_{\phi} \cdot \mathbb{x}_j \quad \Rightarrow \quad \theta(\mathbb{x})= W_{\theta} \cdot \mathbb{x}; \quad \phi(\mathbb{x})= W_{\phi} \cdot \mathbb{x}$
于是,
$y=\text{softmax}(\mathbb{x}^T \cdot W_{\theta}^T \cdot W_\phi \cdot \mathbb{x}) \cdot g(\mathbb{x})$
这和 Attention is all you need 提出的 Self-attention 一致:
$Attention(Q,K,V)= softmax(\frac {QK^T}{\sqrt d_k}) V $
GAN的 Self-Attention
待补坑
基于 Attention 的字符识别
待补坑
基于 Attention 的图片生成
待补坑
强化学习中结合 Attention
Deep Attention Recurrent Q-Networ
最早结合 Attention 到 RL 中的文章
Deep Attention Recurrent Q-Network 在空间进行加权,这里的空间是图片输入 CNN 之后得到的特征空间 features map。具体做法如下图:
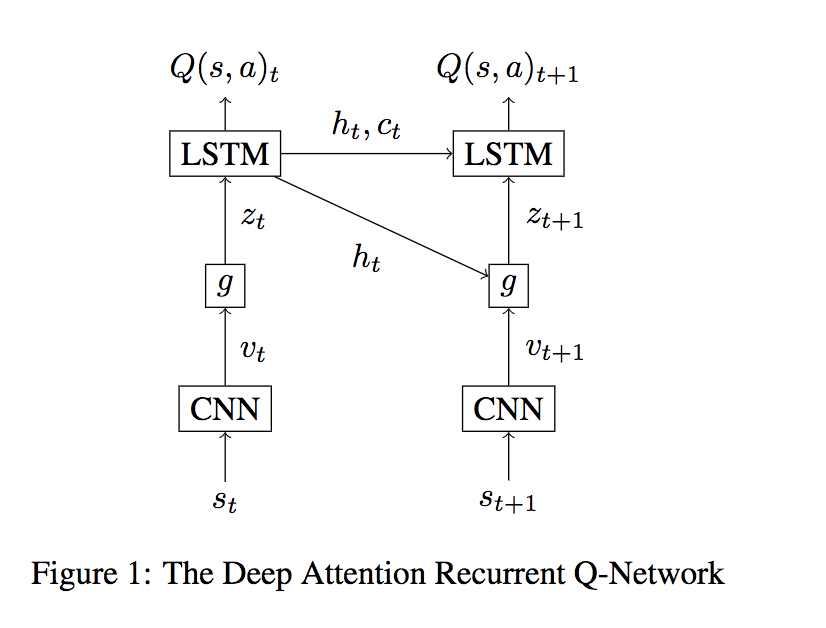
本文和 Show, Attend and Tell: Neural Image Caption Generation with Visual Attention 类似,通过计算隐状态 $h_t$ 和 $v_{t+1}$ 的相似性,得到 $Attention \; Score \; \alpha$, 然后计算 $v_{t+1}$ 的加权平均得到 $z_{t+1}$,作为 DQN(使用 LSTM)的输入。
同样的,本文也有 Soft attention 和 Hard Attention 两种计算方式。
Soft Attenton
$the \; context \; z_t$ 表示为所有特征空间 $v_t^i$ 的加权和,i 代表特征空间每个特征。
计算 $Attention \; Score \; \alpha$ 的为 Attention Network g:
$$g(v_t^i,h_{t-1}) = exp(Linear(Tanh(v_t^i)+Wh_{t-1})))/Z$$
其中 $Linear(Tanh(v_t^i)+Wh_{t-1}))$ 计算隐状态 $h_t$ 和 $v_{t+1}$ 的相似性,Z 是归一化因子,也就是 Softmax。
最后计算 $Z_t$ :
$$z_t = \sum_{i=1}^L g(v_t^i,h_{t-1})v_t^i$$
Hard Attenton
Hard Attenton 采样的时候要求仅仅从图像也就是特征空间中采样一个 patch。
这个采样可以看成从 $v_t^0 … v_t^N$ 选择一个特征,把这个看成 N 个动作,我们的 Attention Network g 输出就是这 N 个动作的概率,很自然想到使用策略梯度。
策略的更新可以表示为:
$$ \nabla \theta_t^g \propto \nabla_{\theta_t^g} log \pi_g(i_t|v_t,h_{t-1})R_{t}$$
这里的 $R_t$ 是选择 Attention 区域 $i_t$ 后的累计回报。
添加一个新的网络 $G_t = Linear(h_t)$ 用于估计值 $R_t$ ,借鉴 Advantage 的思想,最后 Attention Network 参数更新方式如下:
$$ \theta_{t+1}^g = \theta_t^g + \alpha \nabla_{\theta_t^g}log \pi_g(i_t|v_t,h_{t-1})(G_t - Y_t)$$
其中 $Y_t = r_t + \gamma max_{a_{t+1}} Q(s_{t+1},a_{t+1})$,Advantage 部分为 $(G_t - Y_t)$
除了 Attention Network,model 剩余的部分和 DQN 基本上一致
实验
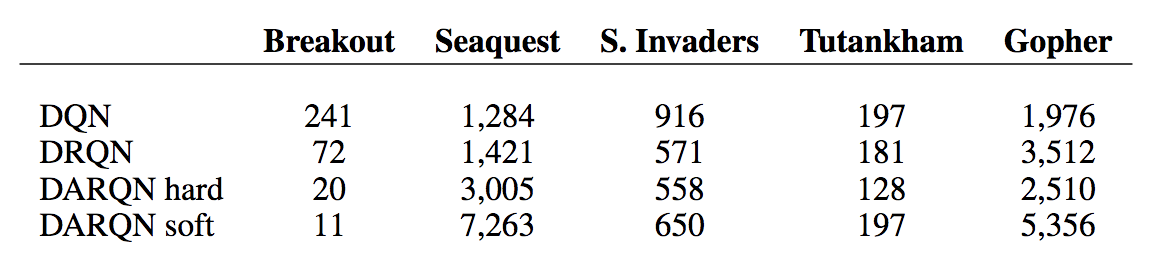
可以看出,这种简单的设计并没有体现出加入 attention 的优势。
Control of Memory, Active Perception, and Action in Minecraft
Control of Memory, Active Perception, and Action in Minecraft 是对记忆进行加权,也就是对输入 state sequence 进行加权。

如上所示,一共有I型迷宫、匹配迷宫、随机迷宫和带指示器的随机迷宫4种迷宫。每种迷宫的任务设计即有相似,又有区别:
I型迷宫: 在此迷宫中,有一个指示器,其颜色为绿色或黄色,两种颜色出现的几率一致。当指示器颜色为绿色时,史蒂夫需要前往蓝色处得到+1的奖励,如果去了红色处,则会得到-1的惩罚。当指示器颜色为绿色时,情况相反。
匹配迷宫: 在此迷宫中,有两个房间。如果两个房间中底板的图样一致,史蒂夫需要前往蓝色方块处,得到+1奖励,如果去了红色则-1。如果两个房间中底板的图样不一致,那么情况相反。
随机迷宫: 迷宫的形态每次都是随机产生的,其中有两种类型的任务:
- 单一目标:找到蓝色方块+1奖励,如果过程中触碰了红色方块则惩罚-1。
- 顺序目标:先踩上红色方块得到+0.5奖励,再踩上蓝色方块得到+1奖励。如果踩方块顺序错误,则得到-0.5和-1的惩罚。
带指示器随机迷宫: 情况和随机迷宫类似,但是有指示器,会显示绿色或者黄色,两种颜色显示概率相等,也有两种任务:
- 有指示器的单一目标:如果指示器是黄色,那么找到红色方块得到+1奖励,踩上蓝色方块则-1惩罚(史蒂夫的第一次死亡正是在这种情况下)。如果指示器是绿色,那么那么找到蓝色方块得到+1奖励,踩上红色方块则-1惩罚。
- 有指示器的顺序目标:如果指示器是黄色,那么史蒂夫要先踩上蓝色方块,再踩上红色方块。如果指示器是绿色,那么史蒂夫要先踩上红色方块,再踩上蓝色方块。顺序正确则分别得到+0.5和+1的奖励,顺序错误就得到-0.5和-1的惩罚。
这些任务被称为认知启发任务(Cognition-inspired tasks)。也就是说,这些任务需要一定的认知能力才能完成。想象一下我们人在这些迷宫中做这些任务。我们需要思考(比如碰到红色会电死),我们需要记忆(比如匹配迷宫任务中两个房间的形状),我们甚至需要推理(比如匹配迷宫中如果房间形状相同则选择蓝色),我们还需要决策(也就是每一个时刻应该往左边走还是右边走)。
本文设计了一个 Memory 结构,具体如下:
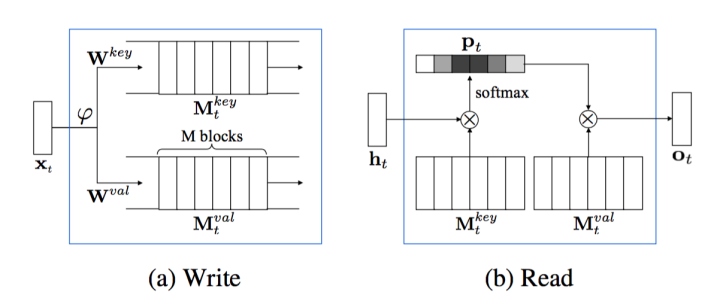
很明显可以看出这是一个 soft attention,整个 model 包含三个部分 Encoding, Memory and Context
Encoding
这一步和DQN的神经网络一样,就是使用一个CNN来提取特征,不同的是这里只是到全连接层,目的是为了获取经过CNN压缩的图像特征信息。上图的 $\varphi$ 就是表示这个卷积处理的过程。
$$ e_t = \phi^{enc}(x_t)$$
Memory
Write:
$$M_t^{key}=W^{key}E_t$$
$$M_t^{val}=W^{val}E_t$$
其中的 W 是参数。输入是已经编码的图像特征信息 $E_t = concate(e_{t-1},e_{t-2},…,e_{t-M})$,输出就是存起来的“记忆”M。
Read
$Attention \; score \; \alpha$ 计算如下:
$$p_{t,i} = \frac{exp(h_t^TM_t^{key}[i])}{\sum^M_{j=1} exp (h_t^TM_t^{key}[j]))}$$
Attention Context (在本文被称为 Memory):
$$o_t = M_t^{val}p_t$$
Context
加入 $ o_t$ 后,LSTM 的更新公式为
$$ [h_t,c_t] = LSTM([e_t,o_{t-1}],h_{t-1},c_{t-1})$$
也就是把上一个时刻提取的记忆也作为输入
最后计算 Q 函数公式如下:
$$ q_t = \varphi^q(h_t,o_t)$$
FRMQN 的结构如下:
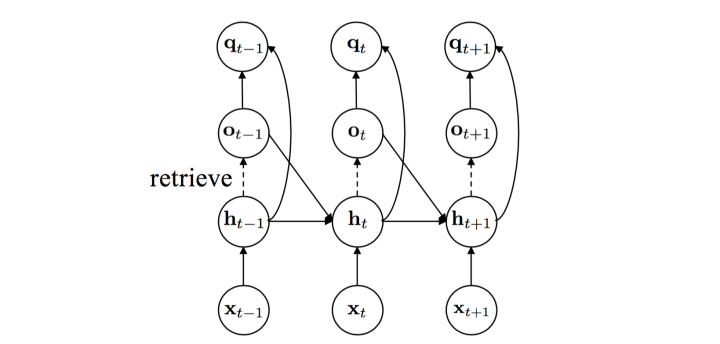
我们都知道LSTM也是一个记忆模块,那么为什么还专门弄一个 Memory 呢?
LSTM影响的是 Context 上下文。而 Memory 则可以直接影响最后的Q值。两者的作用不一样。从功能实现上看,Memory更具化某一个记忆而且是最近的M次观察的记忆,而LSTM则是累积整个时间序列的记忆。
实验
以匹配迷宫任务为例,我们观察下面这张图表:
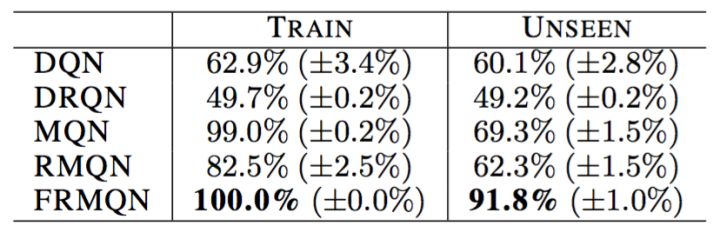
通过训练,使用FRMQN结构的算法最后能够在训练集的所有任务中顺利达成目标。而算法在面对其并没有见过的测试用的匹配迷宫时,凭借它在训练中的得到的“经验”,顺利达成任务的概率是91.8%。
Multi-focus Attention Network for Efficient Deep Reinforcement Learning
Multi-focus Attention Network for Efficient Deep Reinforcement Learning 来自 AAAI 2017 Workshop on What’s next for AI in games 提出了一个 Multi-focus Attenion Network,可以应用到 Single Agent 和 Multi-Agent。

上图是一个 grid world 导航任务的地图。每个 cell 代表这个地图的一个像素点,整个地图就是模型的输入。Agent A 按照(W1,W2,W3,W4) 的顺序依次访问每个 cell 。两幅图中,W1 的绝对位置不同,但是相对 A 的位置相同。因此,如果 RL model 学会了左边的图的策略,那么它在学右图的任务时应该可以 faster 。然而,这两张图对于 DQN 来说是完全两个不同的 states。所以,学习右图 A 到 W1 是一个独立的过程。前面介绍的 DARQN 算法,只有一层 attention ,只学习到了一种 entities 的关系。
于是,本文提出了 Multi-focus Attention Network,尝试学习多种 Attentions。
Multi-focus Attention Network
整个 model 分为四个部分,(a) Input segmentation, (b) Feature extraction, (c) Parallel attentions, (d) State-action value estimation。
Input segmentation
这个模块将输入简单分成多个 segments ,将其称为 partial states。具体做法,将输入图像划分成均匀的 grid ,有规则的选择 cells 作为 partial state。
Feature extraction
这个模块是为了构建 Key Value。
对于每个 partial state,先通过一个公共的特征提取层,比如 CNN。
$$ c_i = f_f(s_i) \; for \; all \; i \in (0,1,…,K)$$
然后构建 Key 和 Value:
$$Key_i = W_{key} \cdot c_i$$
$$Val_i = f_v(W_{val} \cdot c_i)$$
其中的 i 都表示第 i 个 partial states,$f_v$ 代表激活函数
Parallel attentions
为了学到不同的 Attentions,我们就要有不同的 Query ,这里不再使用 RNN 中隐状态作为 Query。本文定义了 N 个 selector vector $a_0,a_1,…,a_{N-1}$ 作为 N 个 Query。
于是可以得到 N 个 Attention Score:
$$A_i^N = \frac{exp(a_n \cdot Key^T_i)}{\sum_j exp(a_n \cdot Key_j^T)} \; for \; all \;n \in (0,1,…,N-1)$$
所有的 $a_n$ 都在训练之前随机初始化,为了让不同的 attention layers 学到不同的 attentions ,还加入了正则化,这里不再赘述。
State-action value estimation
很自然地,我们可以得到 N 个 context vector h:
$$ h_n = \sum_i Val_i \cdot A_i^n$$
接着我们把 N 个 vector 拼接起来 :
$$ g = concat(h_0,h_1,…,h_N) $$
g 就是最后计算 Q 函数的输入:
$$ Q = f_q(g)$$
Extension to the Multi-Agent Reinforcement Learning
在 Multi-Agent 的任务中,每个 Agent 观察的是 partially atates,是整个环境状态的一部分。
Input segmentation
和 Single Agent 一样,不再赘述
Feature extraction
$$ c_i = f_f(s_i) \; for \; all \; i \in (0,1,…,K)$$
然后构建 Key 和 Value,Query:
$$Key_i = W_{key} \cdot c_i$$
$$Val_i = f_v(W_{val} \cdot c_i)$$
$$ a_i = W_a\cdot c_i$$
这里的 i 不再表示第 i 个 partial states,而是表示第 i 个 Agent。注意到这里的 Query 和前面不一样了。
于是可以得到 K 个 Agent 的 Attention Score:
$$A_j^i = \frac{exp(a_i \cdot Key^T_j)}{\sum_{j’} exp(a_i \cdot Key_{j’}^T)} \; for \; all \;i,j \in (0,1,…,K)$$
$A_j^i$ 表示 Agent j 对 Agent i 的权重。越高表示Agent j 拥有对 Agent i 更有用的信息。
State-action value estimation
同样地,我们可以得到 K 个 Agent 的 context vector h:
$$h_i = \sum_j Val_j \cdot A_j^i \in (0,1,…,K)$$
$$g = concate(Val_i,h_i)$$
这里 $h_i$ 是第 i 个 Agent 的 communication feature
最后计算每个Agent 的 Q 值:
$$ Q_i = f_q(g_i)$$
实验
https://www.youtube.com/watch?v=SgTPicFbj5Q
Relational Deep Reinforcement Learning
Relational Deep Reinforcement Learning 使用了 Self-Attention 在空间进行加权。
实验做的好
Relational recurrent neural networks
Relational recurrent neural networks 使用了 Self-Attention 对记忆进行加权。
Multi-Agent 中结合 Attention
待补坑
REF:
- https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html
- https://zhuanlan.zhihu.com/p/37601161
- https://medium.com/@bgg/seq2seq-pay-attention-to-self-attention-part-1-%E4%B8%AD%E6%96%87%E7%89%88-2714bbd92727
- https://jhui.github.io/2017/03/15/Soft-and-hard-attention/
- https://medium.com/@bgg/seq2seq-pay-attention-to-self-attention-part-2-%E4%B8%AD%E6%96%87%E7%89%88-ef2ddf8597a4
- https://zhuanlan.zhihu.com/p/33345791
- https://zhuanlan.zhihu.com/p/21320865