
强化学习的特点(不同于其他机器学习):
- 没有监督数据、只有奖励信号
- 奖励信号不一定是实时的,而很可能是延后的,有时甚至延后很多。
- 时间(序列)是一个重要因素
- 当前的行为影响后续接收到的数据
The RL Problem
奖励 Reward
- 一个Reward $R_{t}$ 是信号的反馈,是一个标量
- 它反映 Agent 在 t 时刻做得怎么样
- Agent 的工作就是最大化累计奖励
强化学习主要基于这样的”奖励假设”:所有问题解决的目标都可以被描述成最大化累积奖励。
序列决策 Sequential Decision Making
- 目标:选择一系列的 Action 以最大化未来的总体奖励
- 这些 Action 可能是一个长期的序列
- 奖励可能而且通常是延迟的
- 有时候宁愿牺牲即时(短期)的奖励以获取更多的长期奖励
个体和环境 Agent & Environment
可以从个体和环境两方面来描述强化学习问题。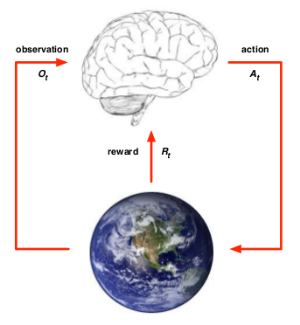
在 t 时刻,Agent 可以:
- 做出一个行为 $A_{t}$
- 有一个对于环境的观察评估 $O_{t}$
- 从环境得到一个奖励信号 $R_{t}$
Environment 可以:
- 接收 Agent 的动作 $A_{t}$
- 更新环境信息,同时使得Agent可以得到下一个观测 $O_{t+1}$
- 给Agent一个奖励信号 $R_{t+1}$
历史和状态 History & State
历史
历史是观测、行为、奖励的序列: $H_{t} = O_{1}, R_{1}, A_{1},…, O_{t-1}, R_{t-1}, A_{t-1}, O_{t}, R_{t}$
状态
状态是所有能够决定将来的已有的信息,是关于历史的一个函数:$S_{t} = f(H_{t})$
环境状态 Environment State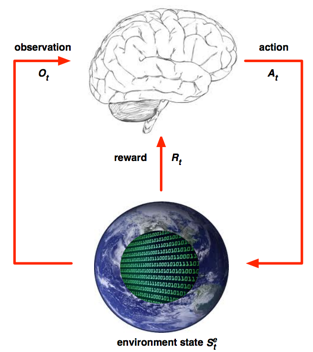
- 是环境的私有 representation
- 包括环境用来决定下一个观测/奖励的所有数据
- 通常对Agent并不完全可见,也就是Agent有时候并不知道环境状态的所有细节
- 即使有时候环境状态对Agent可以是完全可见的,这些信息也可能包含着一些无关信息
个体状态 Agent State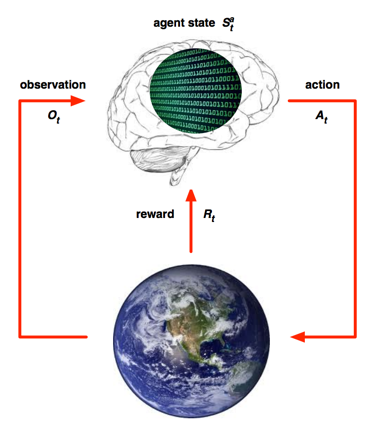
- 是Agent的内部representation
- 包括Agent可以使用的、决定未来动作的所有信息
- Agent State是强化学习算法可以利用的信息
- 它可以是历史的一个函数: $S^{a}_{t} = f(H_{t})$
信息状态 Information State
包括历史上所有有用的信息,又称Markov状态。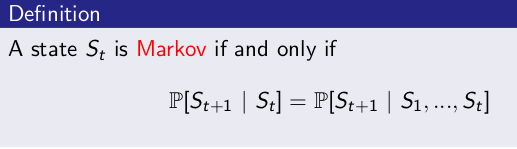
也就是说:
- 如果信息状态是可知的,那么历史可以丢弃,仅需要 t 时刻的信息状态就可以了。例如:环境状态是Markov的,因为环境状态是环境包含了环境决定下一个观测/奖励的所有信息
- 同样,(完整的)历史 $H_{t}$ 也是Markov的。
完全可观测的环境 Fully Observable Environments
Agent能够直接观测到环境状态: $O_{t} = S^{a}_{t} = S^{e}_{t}$
正式地说,这种问题是一个马尔可夫决策过程(Markov Decision Process, MDP)
部分可观测的环境 Partially Observable Environments
Agent 间接观测环境。举了几个例子:
- 一个可拍照的机器人Agent对于其周围环境的观测并不能说明其绝度位置,它必须自己去估计自己的绝对位置,而绝对位置则是非常重要的环境状态特征之一;
- 一个交易员只能看到当前的交易价格;
- 一个扑克牌玩家只能看到自己的牌和其他已经出过的牌,而不知道整个环境(包括对手的牌)状态。
在这种条件下:
个体状态 ≠ 环境状态
正式地说,这种问题是一个部分可观测马尔可夫决策过程 (POMDP)。Agent 必须构建它自己的状态 representation $S^{a}_{t}$,比如:
- 记住完整的历史: $S^{a}_{t} = H_{t}$
这种方法比较原始、幼稚。还有其他办法,例如 :
- Beliefs of environment state:此时虽然 Agent 不知道环境状态到底是什么样,但Agent可以利用已有经验(数据),用各种 Agent 已知状态的概率分布作为当前时刻的 Agent 状态的呈现:
$S^{a}_{t} = (P[S^e_t=s^1],…,P[S^e_t=s^n])$ - Recurrent neural network:不需要知道概率,只根据当前的Agent状态以及当前时刻Agent的观测,送入循环神经网络(RNN)中得到一个当前Agent状态的呈现:
$S^{a}_{t} = \sigma(S^e_{t-1}W_s + O_tW_o)$
Agent的主要组成部分
强化学习中的Agent可以由以下三个组成部分中的一个或多个组成:
1. 策略 Policy
策略是决定Agent行为的机制。是从状态到行为的一个映射,可以是确定性的,也可以是不确定性的。
- 确定的 Policy : $a=\pi(s)$
- 随机 Policy : $\pi(a|s) = P[A_t=a|S_t=s]$
2. 价值函数 Value Function
- 是一个对未来奖励的预测
- 用来评价当前状态的好坏程度
当面对两个不同的状态时,Agent可以用一个Value值来评估这两个状态可能获得的最终奖励区别,继而指导选择不同的行为,即制定不同的策略。同时,一个价值函数是基于某一个特定策略的,不同的策略下同一状态的价值并不相同。某一策略下的价值函数用下式表示:
$V_{\pi}(s) = E_{\pi}[R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+…|S_t=s]$
3. 模型 Model
Agent对环境的一个建模,它体现了Agent是如何思考环境运行机制的(how the agent think what the environment was.),Agent希望模型能模拟环境与Agent的交互机制。
模型至少要解决两个问题:一是状态转化概率,即预测下一个可能状态发生的概率:
$P^a_{s s^{‘}} = P[S_{t+1}=s^{‘}|S_t=s,A_t=a]$
另一项工作是预测可能获得的即时奖励:
$R^a_{s} = E[R_{t+1}|S_t=s,A_t=a]$
模型并不是构建一个Agent所必需的,很多强化学习算法中Agent并不试图(依赖)构建一个模型。
注:模型仅针对Agent而言,环境实际运行机制不称为模型,而称为环境动力学(dynamics of environment),它能够明确确定Agent下一个状态和所得的即时奖励。
Agent的分类
解决强化学习问题,Agent可以有多种工具组合,比如通过建立对状态的价值的估计来解决问题,或者通过直接建立对策略的估计来解决问题。这些都是Agent可以使用的工具箱里的工具。因此,根据Agent内包含的“工具”进行分类,可以把Agent分为如下三类:
- 仅基于价值函数的 Value Based:
在这样的Agent中,有对状态的价值估计函数,但是没有直接的策略函数,策略函数由价值函数间接得到。 - 仅直接基于策略的 Policy Based:
这样的Agent中行为直接由策略函数产生,Agent并不维护一个对各状态价值的估计函数。 - 演员-评判家形式 Actor-Critic:
Agent既有价值函数、也有策略函数。两者相互结合解决问题。
此外,根据Agent在解决强化学习问题时是否建立一个对环境动力学的模型,将其分为两大类:
- Model Free:
这类Agent并不视图了解环境如何工作,而仅聚焦于价值和/或策略函数。 - Model Based:
Agent尝试建立一个描述环境运作过程的模型,以此来指导价值或策略函数的更新。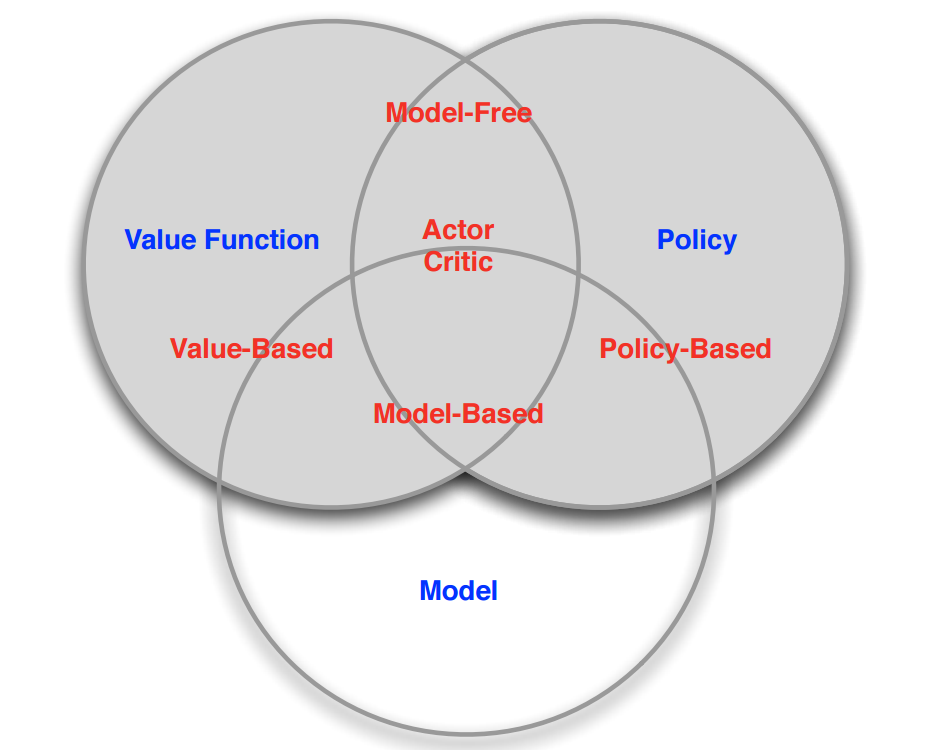
学习和规划 Learning & Planning
学习:
- 环境初始时是未知的
- Agent不知道环境如何工作
- Agent通过与环境进行交互,逐渐改善其行为策略。
规划:
- 环境如何工作对于Agent是已知或近似已知的
- Agent并不与环境发生实际的交互,而是利用其构建的模型进行计算
- 在此基础上改善其行为策略。
一个常用的强化学习问题解决思路是,先学习环境如何工作,也就是了解环境工作的方式,即学习得到一个模型,然后利用这个模型进行规划。
探索和利用 Exploration & Exploitation
强化学习是一种试错(trial-and-error)的学习方式,一开始不清楚environment的工作方式,不清楚执行什么样的行为是对的,什么样是错的。因而agent需要从不断尝试的经验中发现一个好的policy,从而在这个过程中获取更多的reward。
在这样的学习过程中,就会有一个在Exploration和Exploitation之间的权衡,前者是说会放弃一些已知的reward信息,而去尝试一些新的选择,即在某种状态下,算法也许已经学习到选择什么action让reward比较大,但是并不能每次都做出同样的选择,也许另外一个没有尝试过的选择会让reward更大,即Exploration希望能够探索更多关于environment的信息。而后者是指根据已知的信息最大化reward。例如,在选择一个餐馆时,Exploitation会选择你最喜欢的餐馆,而Exploration会尝试选择一个新的餐馆。